Beyond Prompting: Understanding Context for Better AI Results
2025-05-03
Why Context is the Most Important Concept in AI and Why Focusing Too Much on Prompt Engineering Might Be too Shortsighted.
Introduction
In most of discussions about AI, there’s an overwhelming focus on mastering prompt engineering—the art of crafting the perfect instructions to get what you want from an AI model. While prompt engineering certainly matters, there’s a much more fundamental concept that deserves our attention: context.
Understanding how context works and how it influences AI responses is, I believe, the key to truly mastering interaction with large language models.
This article explores why context is the most important concept in AI, how it works under the hood, and why focusing solely on prompt engineering might be leading us astray.
How Does an LLM Work?
Generative AI and LLMs are, in practice, just predictors of next words. There are many approaches to AI and machine learning, but the type that’s causing all the recent hype are GPT-like models that function as next word prediction (or rather next token prediction, to be more precise).
(I’ll try to give my best guided explanation on the subject, getting to the main topic of why context is so important. But I, again, highly recommend the videos from 3blue1brown on LLMs. This one in particular is a great summary that even non-technical folk might be able to follow along. As with all explanation on this topic, I’ll be making many simplifications and analogies.)
What Next Token Prediction is
Let’s pretend I give you a challenge. I wrote a series of numbers in secret. Before showing it to you, I removed the last one and asked you to guess what’s missing.
The sequence is:
1, 2, 3, 4, ___
Was your answer 5?
Okay then, next challenge:
3, 6, 9, 12, ___
Did you guess 15?
What if we change the game to sentences? What’s the missing word?
The sky is ___
I don’t expect you had any trouble guessing “blue.” But why was that? How were you able to guess (or predict) the missing piece?
Throughout your whole life, you’ve been exposed to similar situations, and your brain learned to make connections to determine the most obvious answer. Of course, these silly examples are merely illustrative. But the basis of guessing what comes more to come next, learned through exposure, still applies to more complex examples.
Large Language Models are not that different. They’ve been trained with a huge amount of data, usually written content, hence the name. Through training, they’ve been presented with challenges similar to the ones above and then had the answers revealed to them. After many rounds and many, many challenges, they learn to make connections and embed concepts so they can very fairly predict the next word.
Things get more interesting when you start feeding new data, when there’s no right answer to the missing piece. That’s when the LLM can start to generate content that’s both novel and unpredictable, and mimics human thought.
The whole system implementation is, obviously, much more complex than this, but the fundamentals are just that. You feed it with some text (the prompt), and then it predicts the next word. To make things more dynamic and interesting, there’s usually a setting (called temperature) that allows the LLMs to not always make the most obvious choice, allowing them to be more “creative.”
From One Word to Long Responses
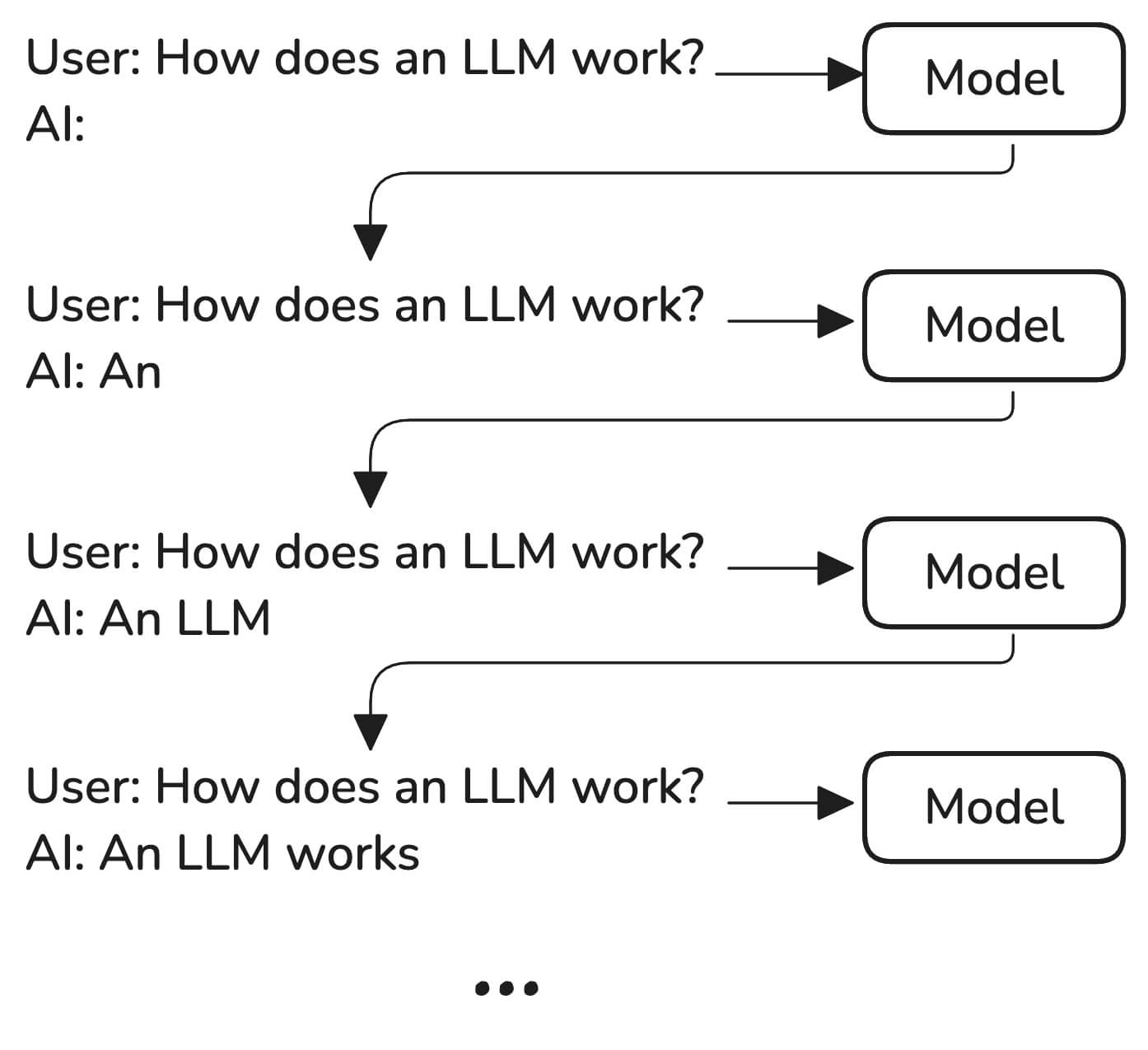
But if LLMs are predicting just the very next word, how can they generate long, detailed responses?
That’s where the first clever trick is applied. After the model has predicted the next word, the whole text, including the recently predicted1 word, is fed back into the system so it can predict the next one, and the next, until it’s satisfied and returns a “stop” signal.
I’m simplifying here, but it’s still useful to think this way: All an LLM does is analyze the whole text it was fed, then predict the next word2. It does this in a loop at such a speed that it feels natural and “human” to us.
(That’s why most LLM interfaces have a streaming UI—that’s this process happening in real time.)
All LLMs Are Stateless
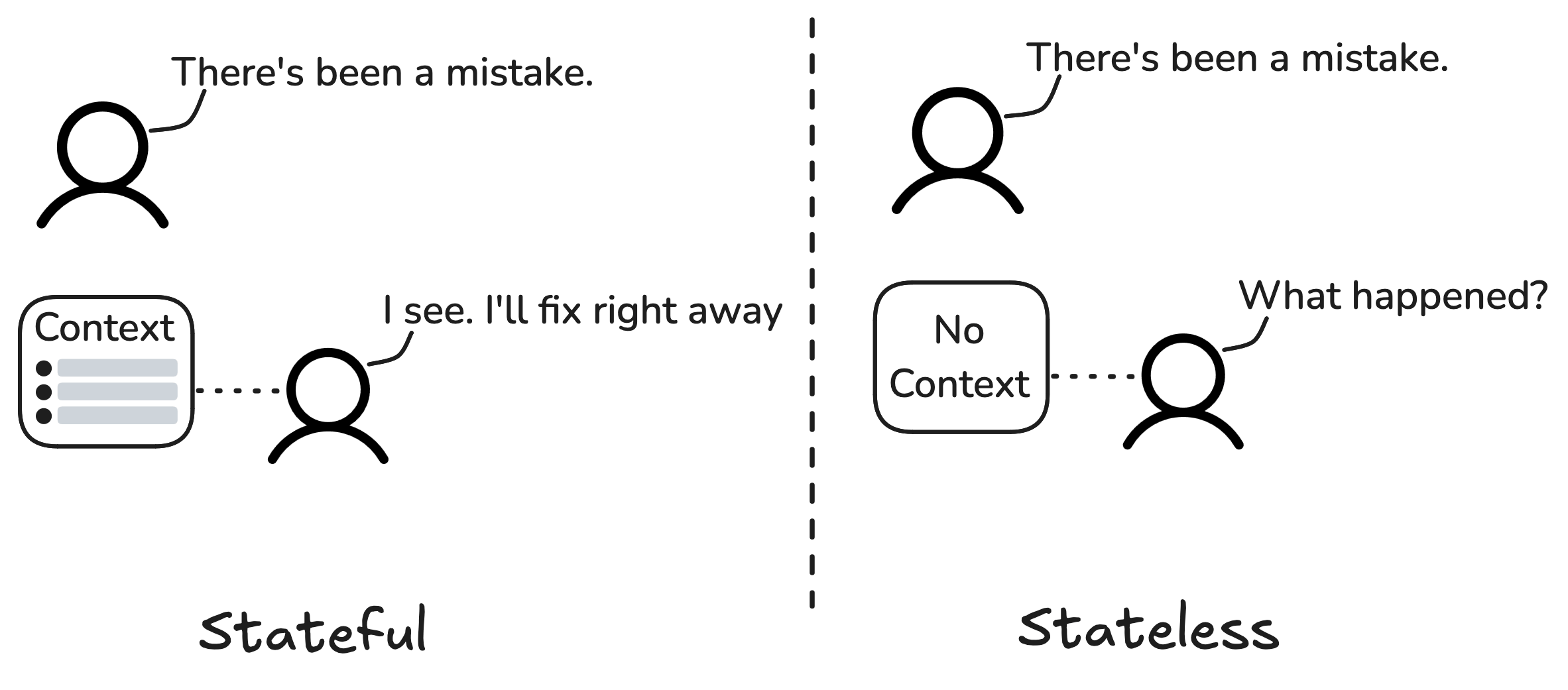
With that in mind, we can introduce another very important concept: LLMs are inherently stateless.
In programming lingo, “stateless” means an operation that’s independent of any additional context. It has no memory of what came before, nor does it save or remember anything after.
Let me try to explain it better with an analogy.
The Restaurant Analogy
Pretend you’re in a restaurant, being served by the same waiter throughout your meal. You talk and interact with the waiter many times throughout your service.
At some point, there’s a problem with your food—you asked for it without rice, but they sent it with rice on your plate anyway. You tell the waiter, “There’s been a mistake.” He rapidly notices what’s wrong, remembers your conversation history, and says he’ll fix it right away.
That’s a stateful interaction. There’s a “state” to be considered and evolved during your time there.
Now, compare that experience with this: You’re at the same restaurant, but this time you’re being served by many different waiters; not once does the same person come back to your table. It’s always a different one, and they can only communicate with the kitchen, never sharing information with each other. This time, every interaction you have with service needs an explanation of the context, of the state.
If you had a problem with your food, you’d have to explain the whole situation to the waiter, explain that you asked for it without rice, that the last waiter explained it wasn’t standard but they would make an exception, but your plate came wrong afterall.
That’s a stateless interaction.
All LLMs are stateless. That means every time you interact with a model, it has no idea what has happened before to help it make its decisions.
“But That’s Not My Experience!”
You’re probably thinking: “I have back-and-forth conversations with ChatGPT, I can ask questions, have it give an answer, then go back and reference something I said four messages ago. How can it be stateless and have no recollection of the past if that’s how I use it all the time?”
We come back to that clever trick. This behavior is possible not because of the model’s internal processing but due to the interface you’re using to interact with the model.
When you send a new message, the interface doesn’t just feed your new text to the LLM to predict the next word; it appends the new message to the entire conversation and feeds everything that was said back to the model.
Going back to our restaurant analogy, you’re still being served by a completely new and different waiter every time you say something. But they are all identical twins who have the same brain structure, and they automatically have access to the whole history of everything you said to the previous person.

That’s how the LLM is able to recall and go back to information that was previously shared. That’s also why most AI interfaces have a “chat-based UI” where you have many different chats, even though, in theory, you’re speaking with the same model.
This explains why it’s a good idea to start a new conversation when things get derailed or you change subjects. That way, you can clean the state and have the model start with a blank canvas.
Understanding Model Context
So when I mention context, that’s what I’m referring to: all the information that’s fed into the model when you request a new answer. Beyond its training weights, that’s everything the model has access to for making its move.
If you want an opinion about a text, what do you do? You paste the text into the chat input and ask the question you’re interested in. The model will take the whole text into consideration before giving its answer.
When you ask a follow-up question, the whole conversation, including the original text, your previous question and the model’s previous response, is sent back for processing so it can keep talking and answering you, taking into account the entire conversation history.
That’s why AI labs always share their models’ “token context window.” That’s the maximum number of tokens the model can take into consideration before running out of processing power. In theory, no model can handle an infinite conversation like we humans do. They’re always only able to process what’s fed to them within that limit.
ChatGPT 3.5 Turbo has a context window of 16,385 tokens, while GPT-4.1 has a context window of up to 1,047,576 tokens. Claude 3.5 and 3.7 have a context window of 200,000 tokens.
How Is It then Possible to Ask Questions About Books or Have AI Remember Facts?
Can you guess? Yes, it’s also through clever interface tricks.
The whole premise of products like NotebookLM is being fed large documents and using them as a knowledge base when interacting with the user. How is this possible if the documents by themselves would exceed the model’s context window?
The answer is a combination of techniques to manipulate the context to better help the LLM. Let’s use an example to illustrate this.
Vector Databases and Retrieval: A Preprocessing Step
You feed two internal company’s operations manuals to NotebookLM; these documents are about 500 pages each.
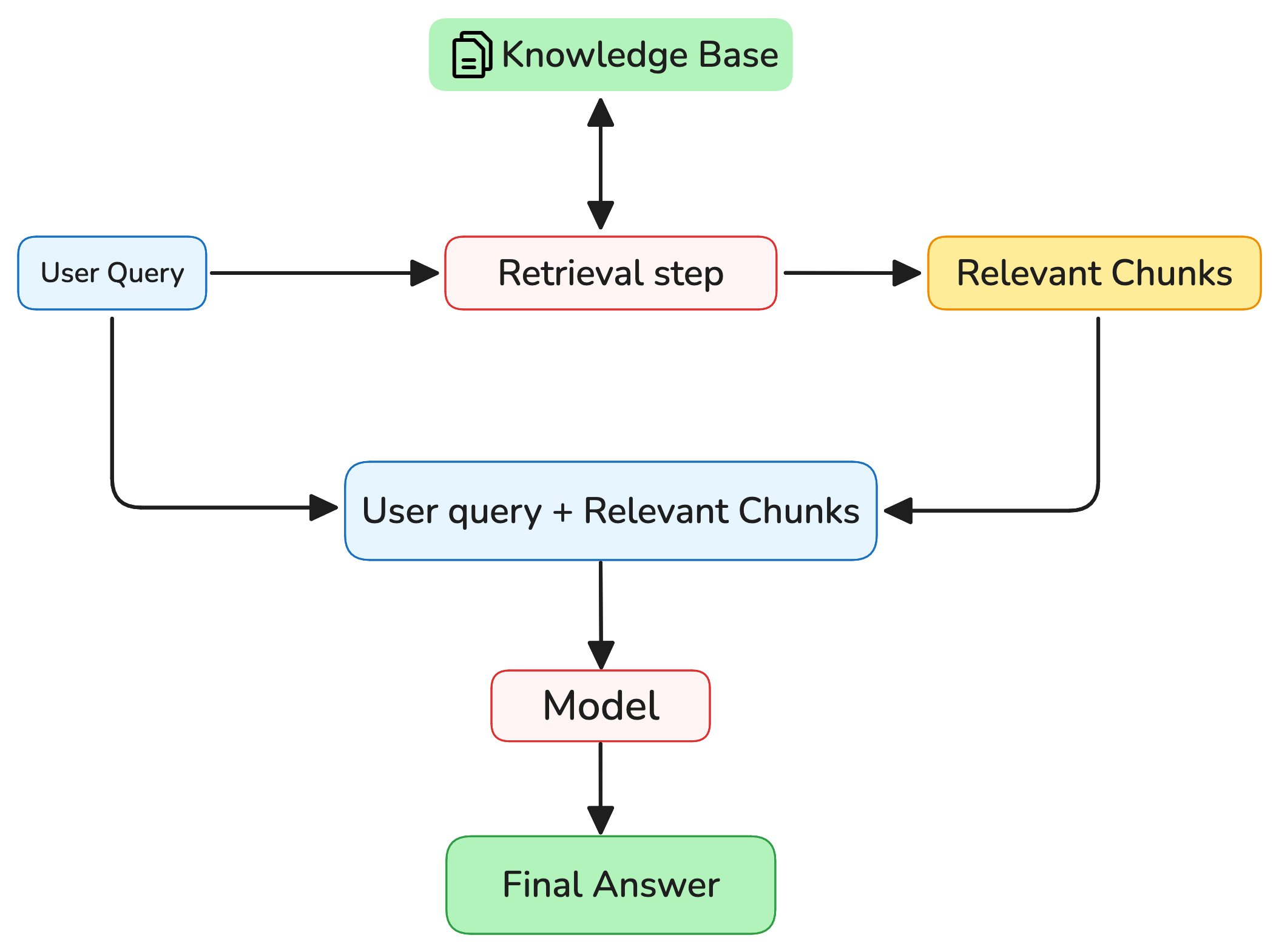
The first thing the system does is to save the documents you uploaded in a special kind of database called a vector database (or vector store). What’s special about this type of database is that it can retrieve content using natural language and semantic meaning. This embedding of documents in the vector database happens as part of the upload process.
So when you write something like, “What’s the policy for travel refunds for managers on international trips?” the system (not the LLM) first scans the vector database for relevant information. It quickly identifies references to travel refunds, managers, or international travel across those 1000 pages. Then, it returns only the relevant chunks of information - perhaps 2 or 3 paragraphs that seem to contain information relevant to the user query.
This entire retrieval process happens before the LLM even gets involved. It’s a separate preprocessing step performed by different components of the system, not by the LLM itself during its inference time.3
Only after this retrieval step does the LLM get involved. The model is then prompt with your query and only with those relevant information chunks retrieved from the entire document. Instead of having to deal with two 500-page books, the LLM has a much easier time handling a one-sentence question and 2 or 3 extra paragraphs of text.
It uses only this data to come up with its answer, not even knowing what’s missing or left out from the original documents.
It’s important to keep in mind that the prompt sent to the LLM is:
- not only the user query;
- not the query plus the whole document’s content;
- it’s just those relevant chunks plus the user query;
- if the interaction keeps going after the model’s initial response, then the conversation history —including the relevant chunks— are used as the prompt. If, in the followup questions, more information is needed, the preprocessing retrieval step acts to get extra relevant information and appends it to the prompt.
This step of retrieving relevant information based on semantic meaning is usually called RAG — Retrieval-Augmented Generation.
Retrieval – Pulling relevant information from a knowledge base (like documents or a database) based on the user’s query.
Generation – Using a language model to generate a response based on both the user’s input and the retrieved information.
The same is true for long-term memory. The system might save relevant information about you that it “learned” from previous conversations, like your favorite coffee shop. When it seems relevant to the current conversation, it retrieves that information and passes it to the model to generate the final response.
Context Limitations and Their Implications
Wait, if the model isn’t aware of the whole document, might that lead to bad answers?
If that thought came to mind while reading the last example, then you’re getting ready to take the most out of AI models.
That key understanding—that LLMs are only aware of their immediate context—is, in my opinion, the most important concept in all of AI.
Why Context Mastery Matters
Really understanding how different contexts will lead to greatly different results will allow you not only to get better results and build better AI-enabled products, but also to understand the potential pitfalls of AI and how to avoid them.
Being a good AI user means being a master at understanding that context is king.
Common Misconceptions About AI
Before we go further, let’s address some common misconceptions that can lead people astray when working with AI systems.
Misconception: “The AI is learning from our conversation”
Many users believe that when they interact with an AI like ChatGPT or Claude, the system is actively “learning” from their inputs and improving itself during the conversation. This is a fundamental misunderstanding of how these systems work.
The “P” in GPT stands for “Pretrained” - these are Pretrained Large Language Models. All the learning happened during the training phase, before you ever interacted with it.
When you chat with an LLM:
- It’s not updating its weights or parameters based on your feedback
- It’s not “getting smarter” the more you talk to it
- It’s not (necessarly) storing your information to improve its general knowledge
- It doesn’t “remember” you or learn your preferences over time on its own (by default)
What’s actually happening is much simpler: the model is using its fixed, pretrained parameters to predict responses based on the current context. Any appearance of learning or improvement comes from two sources:
1 Better context:
As you provide more information in the conversation, the model has more context to work with, which might make its responses seem more personalized or informed.
2 Interface features:
Some AI products have separate systems that store information about users or conversations (mimicking long termmemory), but these are distinct from the core LLM itself.
Misconception: “AI understands the full context”
Even with RAG systems and clever context management, the AI only sees fragments of documents or conversations that are selected for it. It has no awareness of what’s been filtered out or what exists beyond its immediate context window. This limitation is crucial to understand when working with large documents or complex topics.
Beyond Prompt Engineering
Context is not the only thing that will influence an AI’s capabilities; its training data and training strategy, compute power, weight distribution, and more will have an effect on its responses. But considering that, after you choose to use a model, those factors are all fixed. Manipulating the context becomes the best skill to influence its responses.
That’s why I think focusing too much on “prompt engineering” is, sometimes, misleading.
Good prompting is just part of a bigger context.
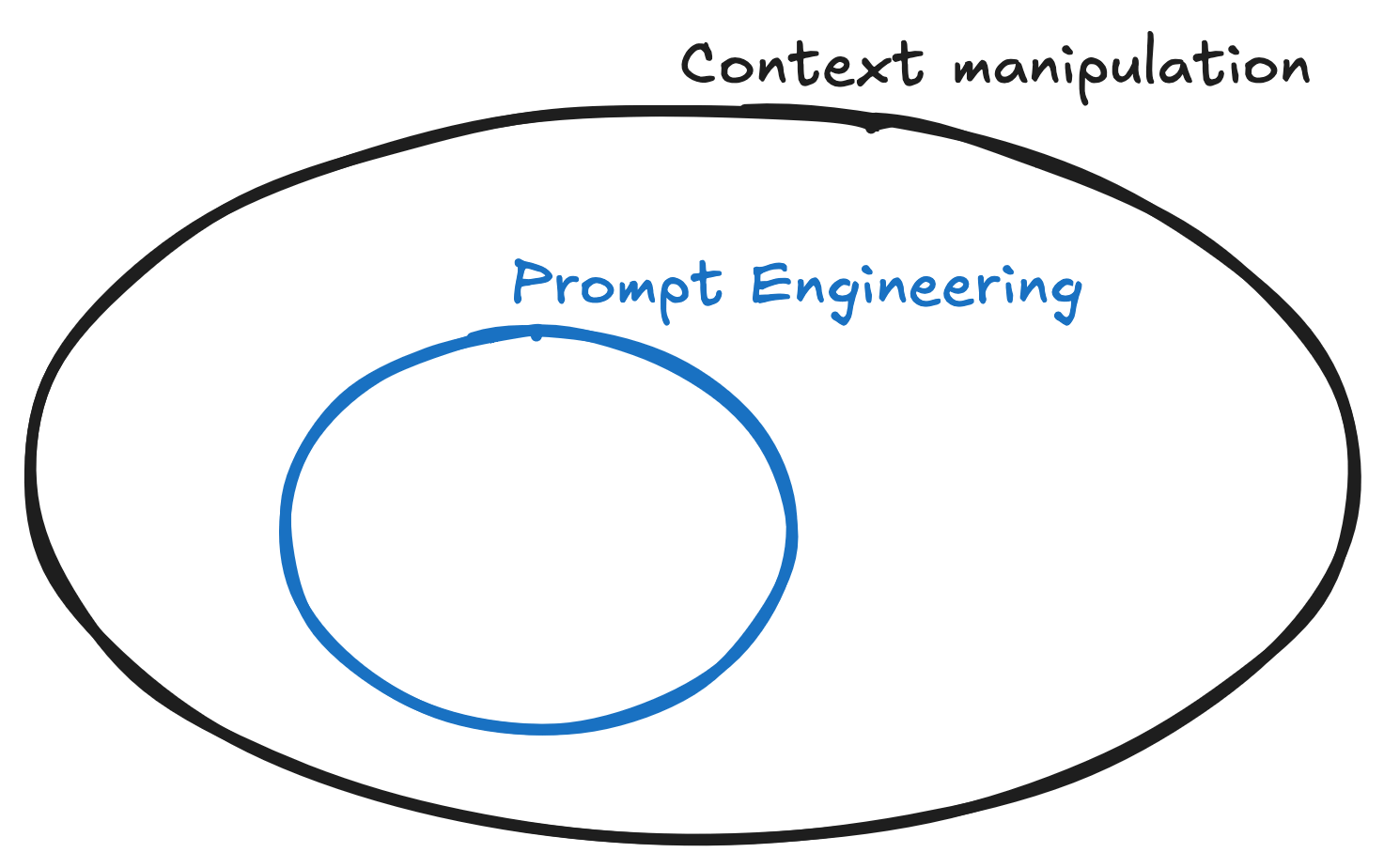
You can spend hours and days trying to come up with a good prompt to get what you want out of a model. But if you don’t consider what the model is aware of while performing its operations, all of that might be in vain.
Cursor website talks a lot about context or context related topics: 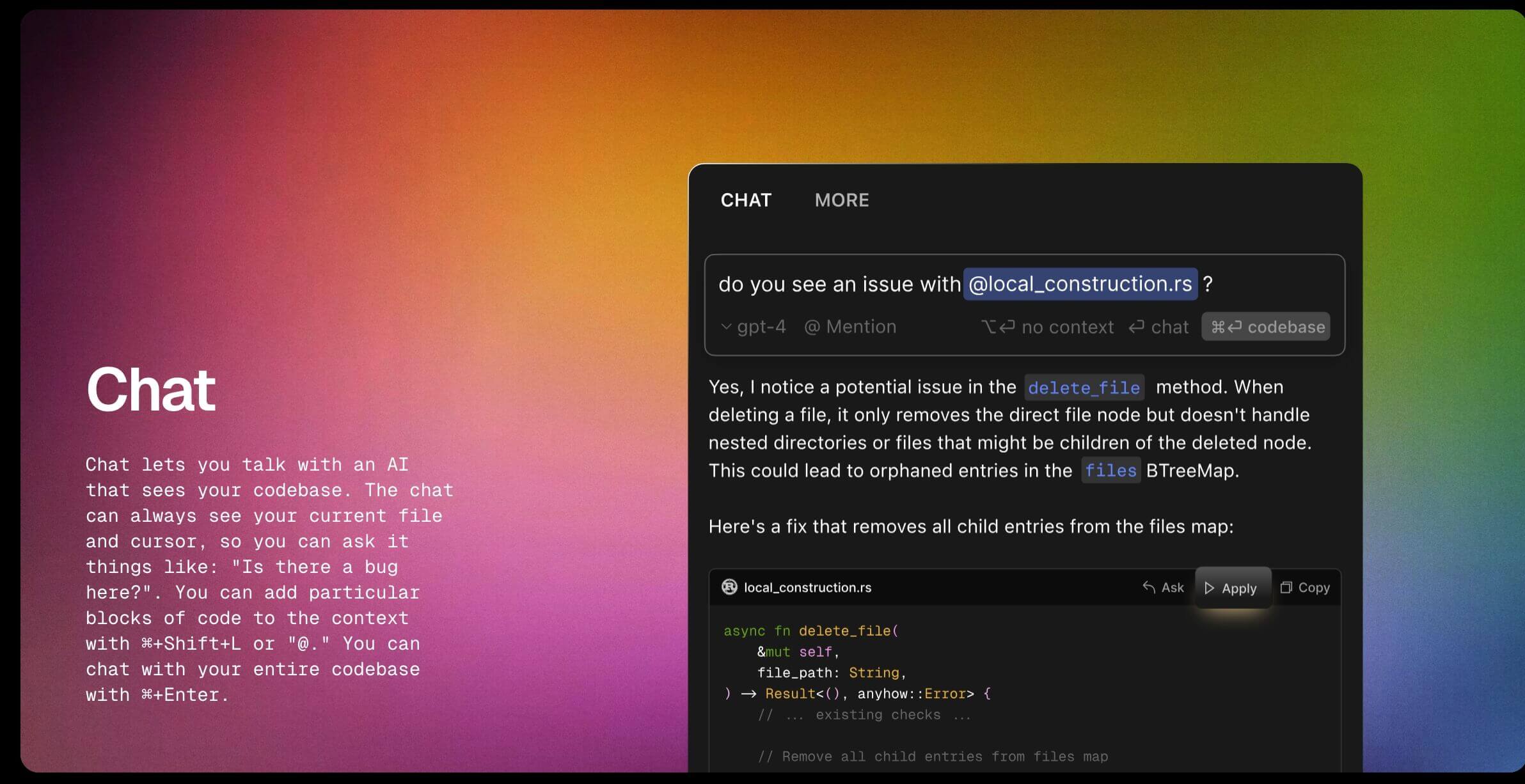
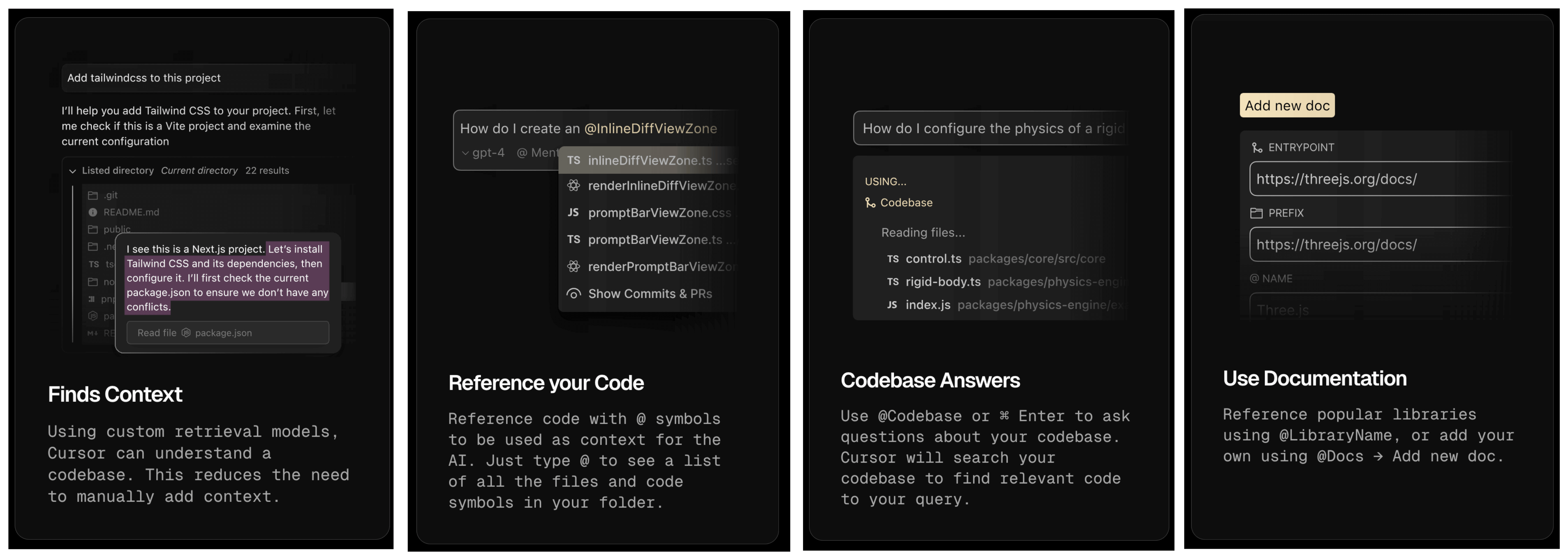
More context is not necessarily better
Context size and availability does not always correlate to better results. Even though it’s usually a good idea to give the model all the relevant information it may need, the key word here is relevant.
Just like a human, if the model is given too much extra and irrelevant information to the question at hand it can get confused and give more importance to some items than they really are. A “dirty context” might steer the LLMs to believe something is true or bias its responses.
If I tell an AI “The sky is green” earlier in our conversation and then later ask “What color is the sky?”, it will likely say “green” or acknowledge that I previously stated it was green. It’s not because the AI believes the sky is green, but because that information was part of its context.
Besides that, even if all the information is relevant, a bigger context will almost inevitably lead to more latency (and cost) in the response. So depending on the application there’s a trade of of speed and accuracy.
Context Management Complexity
I hope to make clear how the understanding and manipulating context is so important to the better use of AI and that is not as simple as it might seem initially.
As users of AI enabled products, in contrast of chatting with a model directly (like in claude.ai or chatgpt.com), we also face a extra difficulty. Some companies don’t make it clear what the whole context of the interaction we’re having is, making it either harder for us to get to the result we want or leaving less experienced users with an underwhelming feeling of AI. (Pete Kooman has a thought-provoking essay on the topic of Horseless Carriages).
A big chunk of the billions of dollars being poured into the AI industry are being given to this exact problem. There are many companies and studies trying to understand the best and most efficient ways to deal with LLM context. Anthropic has a really interesting paper about contextual retrieval and the challenges of deciding what chunks of text documents to give the model for better results. Taranjeet from mem0 published an interesting thread about it too.
Besides RAG and prompting, other areas of studies include:
Context Window Optimization
Techniques for efficiently using limited context windows, including compression, summarization, and strategic truncation of conversation history.
Structured Data Feeding
Methods for converting complex data structures into formats that LLMs can more effectively process within their context.
Dynamic Context Management
Systems that adaptively decide what past information should be included or excluded from the context based on relevance to current queries.
Conclusion
When struggling with getting the right output from an AI model, instead of endlessly tweaking your prompt, take a step back and consider: “What context does the model have access to? What is it aware of and what is it missing?”
Understanding context is the master key that unlocks effective AI use. It helps explain why the same prompt can yield wildly different results in different situations, why AI can sometimes seem inconsistent, and why it doesn’t actually “learn” from your corrections during a conversation.
Complementary reading:
Thinking like an AI
ChatGPT will happily write you a thinly disguised horoscope Claude official documentation on Context Windows
- I’m using the term “predicted” here but “generated” might be more accurate. To the underlying model it’s basically the same thing.↩
- To be more precise an LLM works with tokens, not words. But it’s easier and good enough to make this simplification. Tokens are the “smaller” unit an LLM works with. It’s the information that gets converted into a vector and embedded within its training weights.
This tool from OpenAI is great at visualizing and better explaining what tokens are. (This is an alternative tool from another maker)
 ↩
↩ - This is also a minor simplification. Although many RAG system indeed retrieve information before passing it to the LLM model, there are many ways to approach this challenge. Agents and multi-agents systems are gaining popularity. That’s when the AI can either call itself in a loop, requesting more information if it’s not satisfied with what’s available or use of many distinct models talking and sharing information to each other.↩